

하이퍼리즘 테크팀에서는 이전 글에서 소개했던 BOS, 다양한 슬랙봇, 크립토 특화 정산 프로그램 등을 개발해 최고의 암호화폐 트레이딩 환경을 제공하고 있습니다. 하지만 소규모 인원으로 다양한 서비스를 개발하다 보니 문제가 생겼습니다. 정산 프로그램처럼 도메인 지식과 정확도가 중요한 서비스의 경우, 핵심 시니어 개발자에게 코드 리뷰 업무가 집중되면서 개발이 지연되었습니다.
이 문제를 해결하기 위해 자동화된 1차 리뷰 프로세스를 도입하기로 했습니다. 리뷰어에게 코드가 전달되기 전에, 자동 리뷰로 명백한 문제와 실수를 먼저 걸러내는 방식입니다. 1차 피드백이 잘 제공된다면 리뷰어는 개발자의 실수나 명백한 논리 오류 대신에 비즈니스 로직의 정확도에 더 집중해서 리뷰할 수 있습니다.
이번 글에서는 1차 리뷰 프로세스를 담당하는 PR 리뷰 에이전트를 어떻게 개발했는지 소개하겠습니다.
상용 서비스 vs 자체 개발
같은 문제의식에서 출발한 상용서비스들이 있습니다. 가장 유명한 서비스로는 CodeRabbit이 있습니다. 실제로 다양한 기업들이 사용하고 있고, 리뷰 퀄리티도 1차 피드백용으로 쓴다면 훌륭하지만 몇 가지 문제점이 있었습니다.
첫 번째로 제일 큰 보안 문제가 있습니다. 코드가 유출되어 라자루스 같은 해킹 그룹이 취약점을 발견한다면, 암호화폐를 취급하는 하이퍼리즘 같은 회사는 치명적인 피해를 입을 수 있습니다. 그래서 AI 서비스를 사용하더라도, 데이터 노출을 기존 프로바이더(Google, OpenAI, Anthropic)로 제한하기로 했습니다.
또한, 커스터마이징 문제가 있습니다. 모든 개발 조직이 그렇듯, 하이퍼리즘도 각 셀마다 리뷰 스타일, 중요하게 여기는 포인트, 리뷰에 필요한 도메인 지식이 모두 다릅니다. 만약 코드레빗을 쓴다면 코드레빗에서 제공하는 방식으로 커스터마이징이 제한됩니다. 하지만 직접 개발한다면 필요한 경우 Fork해서 프롬프트를 수정하는 식으로 리뷰 작동 방식을 손볼 수 있습니다.
이런 점들을 고려할 때 상용 서비스를 사용하기 보다는 직접 개발하기로 결정했습니다.
Claude Agent SDK
에이전트를 개발할 때 사용할 수 있는 다양한 에이전트 개발 패키지가 있습니다. Google ADK, OpenAI Agents SDK 등 여러 가지 옵션 중 Claude Agent SDK를 선택했습니다.
Claude Agent SDK는 설치된 Claude Code를 Python/TypeScript로 제어할 수 있는 라이브러리입니다. 이미 개발에 Claude Code를 사용하고 있었기 때문에 Claude Agent SDK를 사용한다면 다른 프로바이더로 코드가 추가로 유출될 위험이 없습니다.
무엇보다 Anthropic이 정교하게 최적화한 Claude Code 에이전트의 능력을 그대로 활용할 수 있다는 점이 매력적이었습니다. 또한 기존 Claude 구독으로 사용할 수 있어 추가 비용이 발생하지 않는데, 에이전트가 실행될 때 많은 양의 토큰을 소비한다는 점을 고려하면 큰 장점입니다.
Naive Prompting 방식
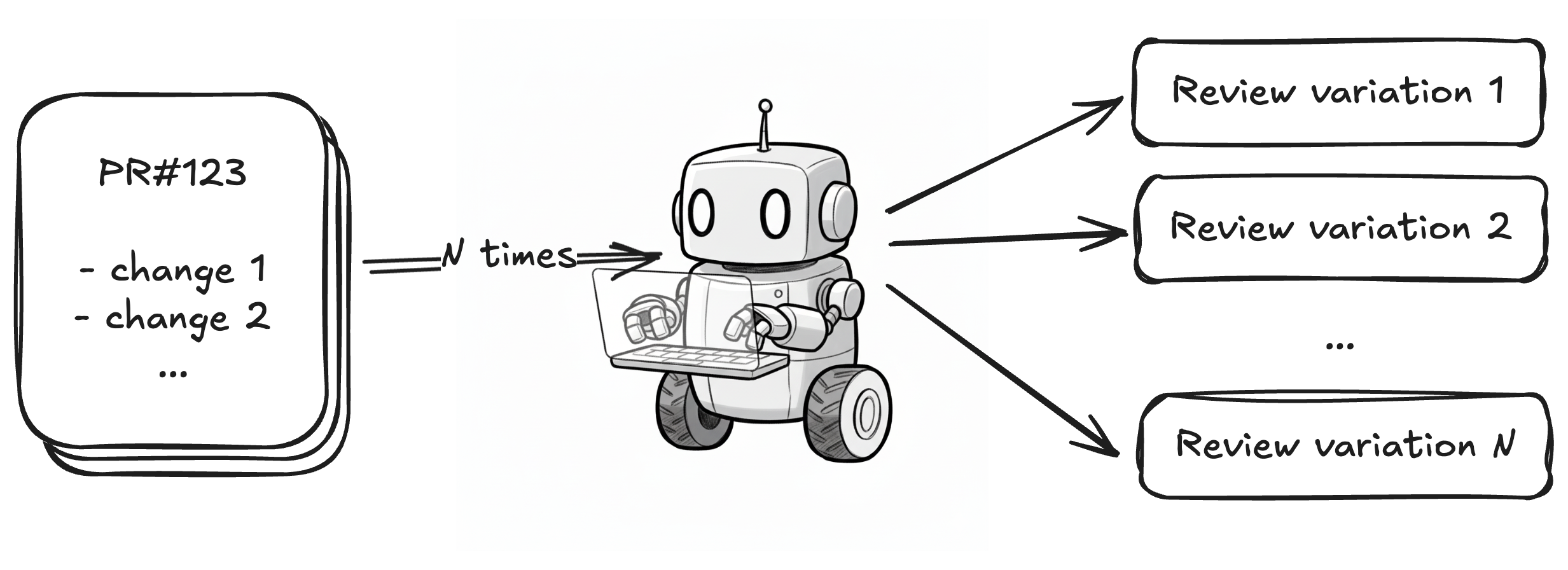
가장 먼저 시도한 것은 리뷰 프롬프트를 입력하고 실행하는 방식이었습니다. Anthropic이 제공하는 Claude Code Action을 사용하는 방식과 거의 동일합니다. 프롬프트만 입력하고 에이전트에게 모든 것을 맡기는 방식입니다.
다양한 방식으로 구현한 에이전트의 리뷰 퀄리티를 비교하기 위해, 모두 특정 PR을 대상으로 리뷰를 실행하고 어떤 이슈들을 잡아냈는지 비교했습니다.
이 방식(Naive Prompting)은 설계 문제, 테스트 커버리지 문제, 명백한 버그 몇 가지를 잡는 데 성공했습니다. 다만 도메인 지식이 필요한 비즈니스 로직 문제나 코드 스타일 통일성 관련 이슈는 잡지 못했습니다. 무엇보다 실행할 때마다 잡아낸 이슈와 설명이 일관성이 없었고 False Positive가 빈번했습니다.
단순 참고용으로 사용한다면 대부분의 팀에게는 Claude Code Action과 커스텀 프롬프트를 활용하는 방식이 관리의 편의성 대비 성능 관점에서 충분합니다. 하지만 저희의 목적이었던 리뷰어의 부담을 줄이기 위한 1차 리뷰 프로세스로 사용하기에는 결과가 불안정하다는 점이 큰 단점이었고, 다른 방식들을 시도했습니다.
Checklist 방식
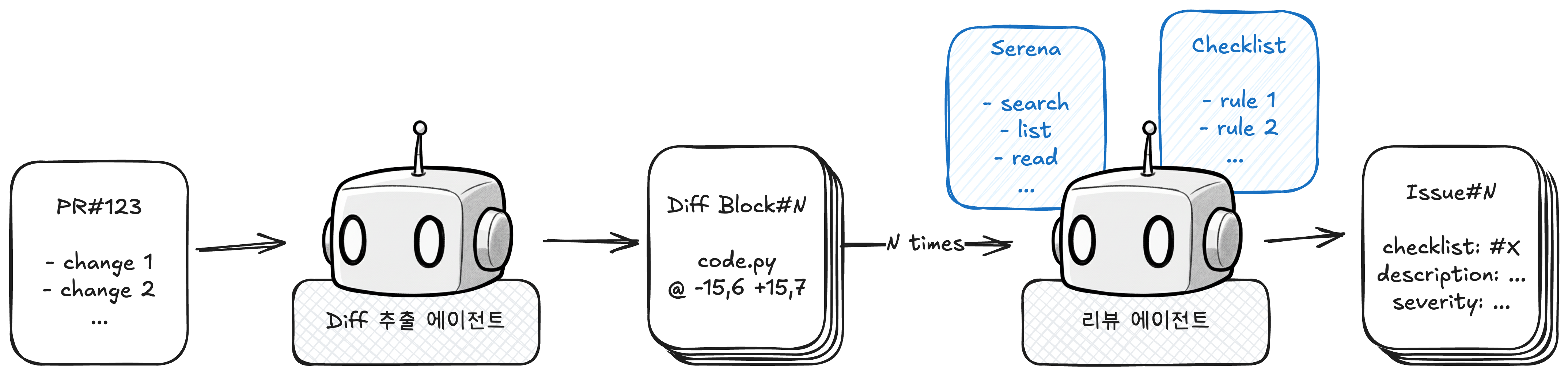
다음으로 시도한 것은 미리 체크리스트를 작성해두고 이를 기반으로 에이전트가 리뷰하는 방식입니다.
- Line-by-Line으로 보지 않기 위해 Diff 추출만 담당하는 에이전트가 PR 정보를 받아서 의미 있는 Diff Block을 생성합니다.
- Diff Block마다 리뷰 에이전트를 생성합니다.
- 리뷰 에이전트는 시스템 프롬프트로 주입된 체크리스트의 각 항목을 Serena(코드 베이스 검색 도구)로 검증하고, 실제 이슈인 경우 리스트에 추가합니다.
이 모든 과정은 Python 스크립트가 제어하고, 각 에이전트는 일종의 함수 역할을 합니다.
이 방식도 Naive Prompting과 동일한 조건으로 테스트했습니다. 체크리스트 기반 방식이다 보니 리스트에 명시된 요소는 확실히 확인했지만, 체크리스트에 없는 영역은 리뷰하지 않아 오히려 Naive Prompting 방식보다 리뷰 품질이 떨어졌습니다. 그 대신 개발자가 제어할 수 있는 영역이 늘어나 더 일관적인 결과가 나왔습니다.
가장 문제였던 것은 여전히 False Positive가 많다는 점이었습니다. 에이전트의 Reasoning 과정을 보니 Serena를 통해 코드베이스를 확인하기는 하지만, 그 과정이 일관되지 않았습니다. 어떤 이슈는 자세히 체크하고 어떤 경우는 빠르게 판단하는 식으로 작동했습니다. 다른 문제들보다 False Positive가 많다는 점이 가장 큰 문제라고 판단해, 최종 방식인 레퍼런스 체크 방식으로 리뷰 에이전트를 개발하게 되었습니다.
레퍼런스 체크 방식
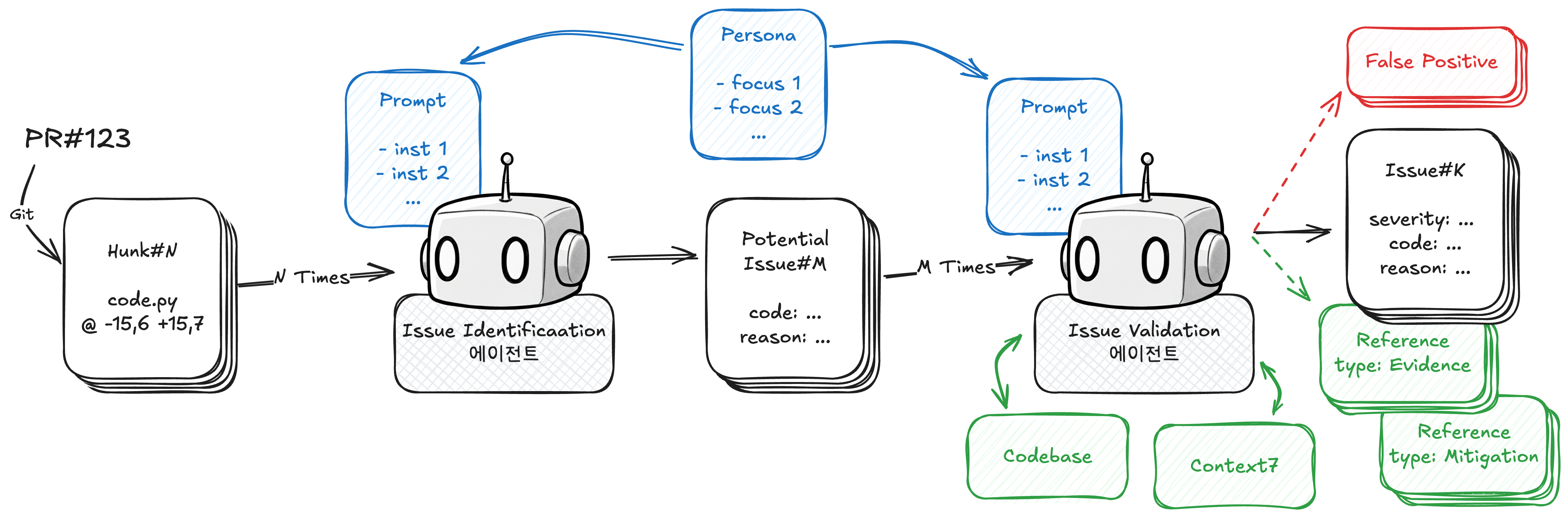
최종적으로 사용한 레퍼런스 체크 방식입니다. 체크리스트 방식과 마찬가지로 Python 스크립트가 전체 과정을 제어합니다.
- Diff 추출 에이전트 대신, Hunk 사용: 에이전트가 추출한 Diff Block을 확인해보니 Git이 기본으로 제공하는 Hunk와 크게 다르지 않아, Hunk를 사용하기로 결정했습니다.
- 2단계 구성: 첫 번째 단계(Issue Identification)에서는 검증 없이 가능한 이슈를 공격적으로 찾아내고, 두 번째 단계(Issue Validation)에서는 레퍼런스를 수집해 False Positive 여부를 검증합니다.
- 이슈별 레퍼런스 수집: 이슈별로 Evidence(이슈가 실제 문제인 근거)와 Mitigation(이슈가 오탐일 수 있는 근거)을 모두 수집합니다. 외부 라이브러리 레퍼런스가 필요한 경우 context7(라이브러리 문서 검색 도구)을 사용합니다.
두 단계 모두 실제 리뷰 데이터를 바탕으로 페르소나를 구성하고, 이를 반영해 간결하게 프롬프트를 작성했습니다. 프롬프트를 통해서 리뷰 시 어떤 부분에 집중할지 어느 정도 제어할 수 있습니다.
시스템 프롬프트에 '근거를 수집해'라고만 작성했을 때보다 Tool Call로 레퍼런스를 추가하도록 했을 때 토큰을 약 50% 정도 더 사용하며 훨씬 적극적으로 레퍼런스를 수집했습니다. 또한 Evidence와 Mitigation을 모두 수집하기 때문에 False Positive를 줄이는 데 확실히 효과가 있었습니다. 테스트한 PR에서는 Potential Issue 57개 중 32개를 False Positive로 판단했습니다.
2단계 구성 덕분에 Naive Prompting보다 더 다양한 이슈를 찾아내면서도 False Positive를 크게 줄일 수 있었습니다. 첫 번째 단계에서 탐색 공간을 공격적으로 확장하고, 두 번째 단계에서 정확도를 확보하는 방식이 효과적이었습니다.
자율성과 일관성 Trade-off
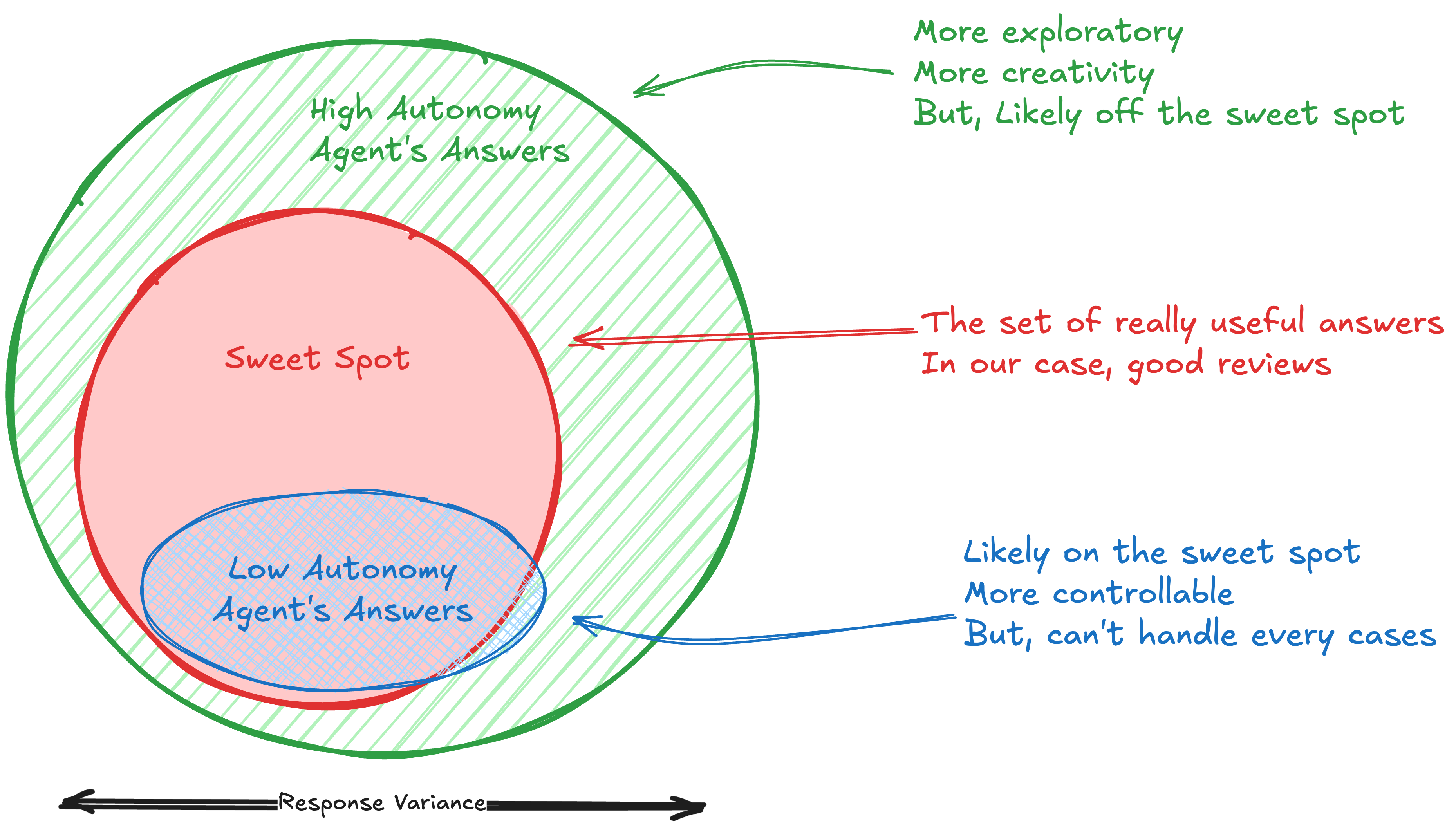
어떻게 해야 에이전트에게 자율성을 줘서 최대한 LLM의 능력을 활용하면서도 일관적인 결과를 얻을 수 있을까
PR 리뷰 에이전트를 만드는 동안 가장 신경 썼던 부분입니다.
간단한 시스템 프롬프트와 도구로 에이전트에게 자율성을 주면, 개발자가 고려하지 못한 케이스까지 잘 처리하면서 LLM의 능력을 최대한 활용할 수 있습니다. 하지만 그만큼 결과의 자유도가 커져서 제어가 어렵고 틀린 답변을 할 가능성이 높아집니다.
반대로 오류를 막기 위해 복잡하고 상세한 시스템 프롬프트와 제약이 많은 도구를 제공한다면, 일관적이고 예측 가능한 정확한 결과를 얻을 수 있습니다. 하지만 체크리스트 방식처럼 리뷰 품질이 낮아지고, 범용적으로 다양한 이슈를 잡아내는 리뷰 에이전트에서는 멀어집니다.
USER: 코드 리뷰해줘 (Naive Prompting의 접근방식)
AGENT: [실행할 때마다 랜덤한 답변, False Positive 많음]
USER: xxx, yyy, zzz 파일 확인하고 aaa, bbb, ccc 중심으로 코드 리뷰해줘 (체크리스트의 접근방식)
AGENT: [일관적이고 정확한 답변, 하지만 범용적으로 쓸 수 없음]
그래서 2단계로 리뷰 과정을 분리하는 것을 선택했습니다. 첫 번째 단계에서는 높은 자율성으로 다양한 이슈를 탐색하고, 두 번째 단계에서는 근거 기반 판단이라는 강한 제약 조건을 적용해 일관적으로 실제 이슈만 남기도록 설계했습니다.
STEP1: 검증 없이 다양한 이슈 찾는 방식으로 리뷰해줘
AGENT: [랜덤하게 다양한 이슈 검출, False Positive 많음]
STEP2: [이슈#N]에 대해서 코드베이스에서 레퍼런스 찾고, Context7에서 라이브러리 문서 찾고 ... 리뷰해줘
AGENT: [해당 이슈에 대해서 일관된 평가기준으로 검증, False Positive 제거]
최종 REVIEW: STEP1 통해서 Naive Prompting 만큼 다양하고, STEP2 통해서는 Checklist만큼 일관적인 리뷰
Agent as Blackbox Function
# 대략적인 리뷰 에이전트 실행 플로우
hunks = get_hunks()
issues = map(hunks, identify_issues)
validated_issues = map(issues, validate_issues)
reviews = aggregate(hunks, validated_issues)
format_and_post(reviews)
# identify_issues, validate_issues 함수는 사실 에이전트입니다.
# input, output 포맷은 고정되어 있지만 실행과정은 완전히 자율적입니다.
하나의 LLM 에이전트가 모든 것을 처리하는 것이 아니라, 여러 단계를 거쳐 리뷰를 생성합니다. 각 에이전트는 정해진 역할만 수행합니다. 그렇기 때문에 에이전트를 일종의 블랙박스 함수로 생각하는 것이 도움이 되었습니다. 입력과 출력은 정해져 있지만 중간 과정은 알 수 없는 함수처럼 다루는 방식입니다. 이런 방식으로 에이전트를 사용하려면 입력을 어떻게 주고 출력을 어떻게 구조화해서 추출할지가 중요합니다.
PR 리뷰 에이전트의 경우 입력은 프롬프트로 전달하고, 출력은 Tool Call로 받도록 설계했습니다. 다음 섹션에서 이 내용을 자세히 살펴보겠습니다.
Tool as Transport Layer
시스템 프롬프트만으로 구조화된 출력 포맷을 강제하려면 한계가 있습니다. 스키마가 복잡해지면 출력이 불완전하거나 불필요한 부연설명이 포함되어서 필터링이 필요합니다. Gemini나 OpenAI API 같은 Single-Turn 호출에서는 구조화된 출력이 비교적 잘 작동합니다. 하지만 Claude Agent SDK 같은 Multi-Turn 에이전트의 경우 어려움이 있습니다. 구조화된 데이터가 중간 답변에 포함되거나, 최종 답변에서 중요 정보가 누락되는 문제가 종종 발생합니다.
Claude Sonnet 4.5 같은 최신 LLM은 Tool Call을 정확하게 수행하고 관련 프롬프트를 잘 따릅니다. 이를 활용해 데이터 전송 전용 Custom Tool을 만들어 구조화된 출력 문제를 해결했습니다. 예를 들어 Issue 목록이 필요하다면 issue_storage.add_issue(code, description)을 에이전트가 호출하고, 호스트 쪽에서는 issue_storage.issues로 결과에 접근하는 방식입니다.
def do_something(args) -> List[Value]:
prompt = PROMPT.format(args)
storage = StorageTool()
agent.run(prompt, tools=[storage])
return storage.values
이 방식을 앞서 설명한 블랙박스 함수 개념과 연결하면, 에이전트를 입출력 스키마가 고정된 함수처럼 사용할 수 있습니다.
결과
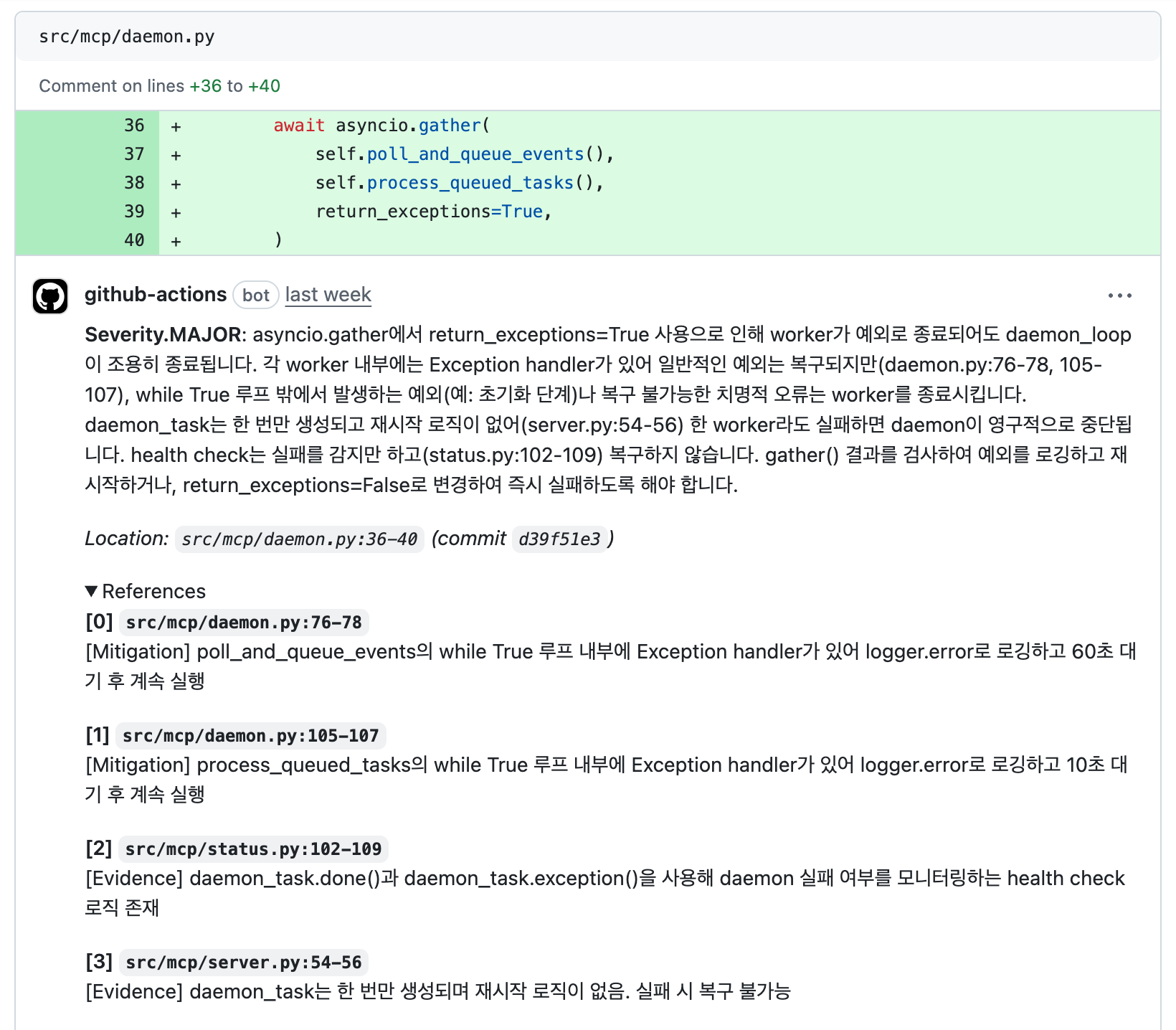
GitHub Action으로 등록하면 실제로 이슈가 있는 코드에 설명과 근거를 함께 덧붙여 리뷰를 남깁니다. 현재는 테크팀 내 정산 프로그램 개발하는 셀에서 시험적으로 도입해 사용하고 있습니다. 아직 도입한 지 얼마 안되어서 샘플이 많지는 않지만, 사용되지 않는 test fixture, 위험한 캐싱 정책, XSS취약점 등 모두 잡아내려면 리뷰 시간이 오래 걸리는 이슈들을 잘 찾아내고 있습니다.
최초 목적이었던 틀린 것, 빠진 것을 찾아내는 1차 리뷰 프로세스 역할은 충분히 수행하고 있습니다. 판단의 근거 또한 레퍼런스로 제공하기 때문에, False Positive가 남아있더라도 개발자가 직접 검토하고 판단할 수 있습니다. 개발자는 PR 리뷰 에이전트의 도움을 받아 더 안전하고 깔끔한 코드를 리뷰어에게 전달하고, 리뷰어는 자잘한 것보다는 중요한 내용에 더 집중할 수 있습니다.
Next Step
여전히 남아있는 문제점들이 있습니다.
- 비즈니스 로직 이슈 리뷰: 지금 버전은 리뷰에 맥락이 필요한 비즈니스 로직 관련 이슈를 발견하지 못합니다. PR이 만들어진 맥락에 대한 정보 없이 PR 변경 사항만 읽고 있기 때문입니다. PR의 내용과 연결된 도메인 지식, 슬랙 대화 같은 맥락 정보를 에이전트에 제공할 수 있다면, 비즈니스 로직 관련 문제도 더 정확하게 잡아낼 수 있을겁니다.
- 여전히 남아있는 False Positive: 여전히 에이전트가 레퍼런스 체크를 건너뛰거나, 실제로 중요한 레퍼런스를 누락하거나, 판단을 잘못하는 경우가 있습니다. 이런 부분을 프롬프트를 수정하거나, 레퍼런스가 없다면 reject하는 식의 룰을 추가해서 개선할 필요가 있습니다.
- 진짜 에이전트: 지금 방식은 에이전트라기 보다는 워크플로우에 가깝습니다. 완전한 에이전트라면 전체 리뷰 과정을 에이전트가 제어해야합니다. 하지만 현재 방식은 Python 스크립트가 제어하고, 에이전트는 특정 기능을 수행하는 함수처럼 사용됩니다. 메인 에이전트와 서브 에이전트 구성으로도 시도했지만, 모든 이슈를 빠짐없이 체크하고 서브에이전트를 누락 없이 생성하는 것은 현재 LLM에게 너무 어려운 과제였습니다. 향후 LLM 성능이 더 향상된다면, 완전한 자율성을 주면서도 프롬프트를 따라서 Sweet Spot에 가까운 답변을 하는 에이전트를 만들 수 있게 되기를 기대하고 있습니다.
이 외에도 개선할 부분이 많이 있습니다. 시험 도입 과정에서 큰 문제가 없다면 천천히 개선해 볼 예정입니다.
마치며
PR 리뷰 에이전트에 대한 글이지만 LLM 에이전트를 어떻게 제어해서 일관적이고 유용한 결과를 만들어낼 수 있을까 고민하시는 분들 모두에게 도움이 되었으면 좋겠습니다.
하이퍼리즘 테크팀은 기술 혁신을 통해 크립토 시장에서 승리한다는 비전 아래 AI를 적극적으로 활용하는 개발, 업무 문화 정착에 노력하고 있습니다. 이러한 여정에 함께할 분들의 많은 지원과 관심을 기다립니다!
☕ 커피챗 문의 - cto@hyperithm.com