

TL;DR
- Karpenter에서 제공하는
expireAfter옵션은disruption옵션과 별개로 동작하는 걸 몰라서 대형 장애가 발생하였습니다. - Pets vs Cattle 라는 개념에 의거하여 Terraform 모듈 형태로 Karpenter를 대체하는 스케일러를 구현했습니다.
- 인프라 Tool은 도입과 철수에 대한 의사결정을 신중히 하는 것이 무엇보다 중요합니다.
주의
본 블로그 글은 정답이 아닙니다. 많은 사람들이 각자의 상황에 맞는 인프라를 갖출 수 있기를 바라는 마음을 담아 작성하였습니다.
소개
안녕하세요, 하이퍼리즘 인프라 셀 DevOps Engineer 오승진입니다.
앞서 소개된 BOS나 Review Bot이 화려하게 무대 위를 누비는 주인공이라면, 인프라 셀은 그 무대가 무너지지 않도록 지탱하고 조명을 비추는 스테이지 크루와 같은 역할을 하는 부서입니다.

보이지 않는 곳에서 시스템을 빌드하고 배포하며 겪었던 치열한 고민 중 커피챗을 했을 때, 많은 분이 물어보시는 특별한 의사결정인 하이퍼리즘 DevOps 팀이 Karpenter를 제거하게 된 이야기를 이번 블로그에 담아보았습니다.
하이퍼리즘의 인프라 설명
하이퍼리즘은 인하우스 환경의 인프라를 제공하고 있습니다.
- 이전에 소개되었던 BOS라는 시스템 또한 인하우스 시스템이지요.
일반적인 B2C 서비스들이 이벤트나 시각에 따라 트래픽이 널뛰는 스파이크형 패턴을 보인다면, 하이퍼리즘의 인하우스 서비스는 비교적 예측 가능한 특성을 보유하고 있습니다. 다양한 트레이딩 봇들의 로직을 미리 알 수 있기 때문에 인프라 트래픽은 대체로 평탄한 형태로 관리할 수 있습니다.
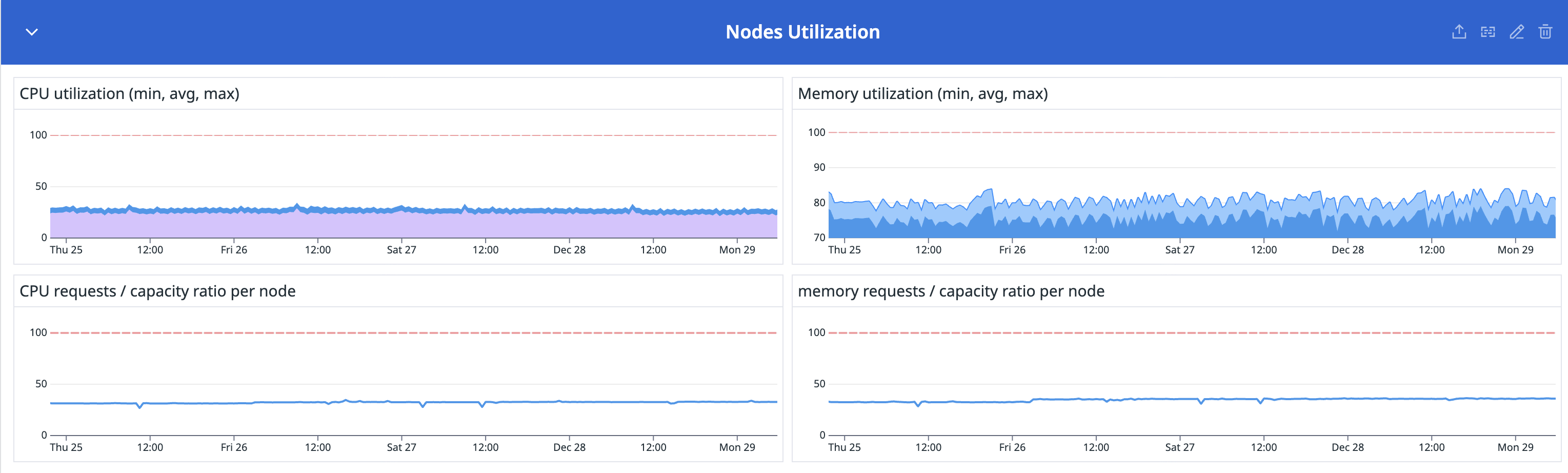
하이퍼리즘은 어떠한 방식으로 스케일을 관리하였을까요?
Karpenter의 시대
하이퍼리즘은 다양한 봇을 동적으로 운영하기 위해 AWS EKS를 사용하고 있습니다.
Worker Node를 관리하는 방법으로는 AutoScaler, Karpenter와 같은 다양한 스케일링 도구를 사용할 수도 있으며 EKS Auto Mode와 같은 AWS Native한 도구 또한 존재합니다.
저희는 이러한 스케일링 도구 중 Karpenter를 사용하였습니다.
단순히 봇이 많아지면 노드를 늘리는 동작을 의도하고 도입하게 되었던 것입니다. 또한, Karpenter를 도입한 당시에는 Terraform, Keycloak과 같은 여러 솔루션을 같이 도입하면서 전반적인 기술 스택 향상이 목적이었습니다.
단순히 남들이 많이 사용한다고 해서 도입한 것도 없지 않아 있었죠.
Karpenter가 장애를 발생시키다
어느 날 봇들이 떠 있는 Worker Node들이 거래 도중 모두 롤링 되는 장애가 발생했습니다.
이런 사태를 방지하고자 사전에 do-not-disrupt 옵션을 true 처리했음에도 롤링 된 것입니다. 봇들은 거래 도중 멈춰버리거나, 아예 종료가 되어버리는 등의 엄청난 스케일의 장애가 발생한 것이었습니다. 이로 인해 모든 봇 운영자가 수동으로 거래 상태를 확인하고 수습하는 사태가 벌어졌습니다.

이는 생산성 향상을 위해 도입한 Karpenter가 인프라의 신뢰도를 크게 퇴보시킨 사건이었습니다. 뒤늦게 파악하기로는, Karpenter에서 제공하는 expireAfter 옵션은 disruption 옵션과 별개로 동작한다는 걸 알아차렸죠. Karpenter의 철학에 따라 최신 AMI를 사용하여 보안 및 성능을 유지하기 위해 비자발적인 롤링이 일어났던 것입니다.

Karpenter 업데이트의 불편함
저희가 사용하던 Karpenter는 0.x 버전이었는데, 1.0 출시와 함께 업데이트를 준비하고 있었습니다. 여기서 문제가 발생합니다. Kubernetes 특성상 커스텀 리소스는 전역적으로 공유하도록 설정되어 있습니다. 그런데 우리가 개발한 BOS에서는 커스텀리소스를 적극적으로 사용하기 때문에 간단한 마이그레이션 외에도 별도의 조치를 추가로 해야만 했습니다.
이로 인해 업데이트의 난이도 또한 만만치 않음을 체감한 상황이었죠. 저희는 Karpenter를 단순히 EC2만 생성하면 되는 존재로 인식하여 도입하였기에 이 사실이 더욱 크게 다가오게 되었습니다.
존재만으로도 상당한 코스트를 유발하는 Karpenter가 마이그레이션 절차까지 복잡하다 보니 인프라 셀은 많은 고민을 하기 시작했습니다.
- 정말 이대로 Karpenter를 계속 사용하는 것이 맞을까?
- Karpenter와 우리 인프라가 잘 안 맞는 것이 아닐까?
- 너무 섣불리 Tool을 도입한 건 아니었을까?
- 대안책은 무엇이 있을까?
철거 결정
결국 인프라 셀은 고민 끝에 Karpenter를 철거하기로 했습니다.
초기 Karpenter 도입의 목적은 'EC2 생성 자동화'를 통한 인적 리소스 절감이었습니다. 하지만 장애 이후 저희가 마주한 현실은 달랐습니다.
- 옵션마다 트레이딩 봇과 주요 서비스에 미칠 영향도를 전수 조사
- 1.x, 언젠가 출시될 2.x 업데이트 시 발생하는 CRD 마이그레이션 공수
- 혹여나 발생할 수도 있는 '비자발적 중단'을 막기 위한 방어적 아키텍처 형태로의 재설계
결과적으로 자동화 도구를 관리하기 위해 투입되는 엔지니어링 리소스가, 자동화로 얻는 이득을 훨씬 웃돌게 되었습니다.
Karpenter가 Hyperithm과 맞지 않았던 이유
DevOps에는 Pets vs Cattle이라는 개념이 존재합니다. 이 개념을 가볍게 풀어보면 다음과 같습니다.
- Pets(애완동물): 아껴줘야 하는 존재, 즉 상태를 주기적으로 보며 문제가 생기면 고치는 등의 행위를 해야 하는 환경
- Cattle(가축): 식별번호로 관리하며, 언제든 다른 가축, 동일한 환경을 가진 서버가 고장 난 서버를 대체할 수 있는 환경
B2B, B2C 플랫폼 K8S 인프라에서 사용되는 Pod은 일반적으로 Cattle로 취급합니다. 각각의 Pod은 Stateless하고 Homogeneous해서 언제든 Scale-out이 가능하기 때문이죠.
- 때로는 Pod이, 때로는 Node가, 때로는 Cluster가 Scale-out이 되기도 합니다.
그럼 이번엔 하이퍼리즘의 BOS라는 서비스로 생각을 해보겠습니다. BOS의 Job은 미션 크리티컬한 거래를 하고 있는 하나의 프로세스입니다. 즉, 각 Job의 생애주기와 거래 스텝에 대한 세세한 관리가 필요한 형태이기 때문에 Pet의 특성을 지녔습니다.
- A ~ D까지의 거래 스텝이 있다고 가정했을 때 B까지 진행됐어도 이 스텝이 '완료'가 되었다는 보장이 없기 때문입니다.
- 물론 DB를 통해 완벽한 State 관리를 한다면 가능하겠지만, 생산성과 로직의 자유도를 위해 희생한 부분입니다.
그러나 Job을 제외한 다른 하이퍼리즘 내부 서비스들은 레플리카가 존재하는 Cattle이기도 하지요.
즉, 하이퍼리즘에서의 Pod은 Pet과 Cattle이 공존하고 있습니다. AutoScaling 같은 동적인 도구는 Cattle을 겨냥해 만들어졌기에, Pet에게 주의를 기울이기에 부적합한 형태가 되기 마련입니다.
- 옵션에 대하여 개별/교집합 케이스를 모두 테스트해서 Pet 시스템에 영향이 있는지 전부 확인을 해야 하기 때문입니다. e.g.) A옵션을 켰을 때 영향이 있는지, B옵션을 켰을 때 영향이 있는지 A, B를 함께 켰을 때 영향이 있는지 등
물론 옵션을 확인하는 작업은 필수이지만 대부분의 Default 값이 Cattle에게 맞춰져 있기 때문에 Pet과 공존하기 위해서 다른 환경보다 더더욱 신경을 더 써야 합니다.
이렇게 결국 생산성을 높여야 하는 도구가 방해꾼이 되는 특이한 현상이 발생하게 되는 것이지요.

Self-Managed 너로 정했다!
우리는 결단을 내렸습니다. 자동화의 화려함을 포기하더라도 완벽한 통제권을 가져오기로 했습니다. 동적 스케일링이 아닌 정적인 수평 확장을 지향하기로 한 것입니다.
그렇다고 해서 완전히 수동 오퍼레이션으로 돌아간 것은 아닙니다. IaC 철칙에 따라 모든 EC2 노드를 Terraform으로 관리하기 시작했습니다.
그럼에도 장애를 겪다
물론 이후에도 저희에게 시련이 찾아왔었습니다. 이번에는 반대로 AMI 업데이트를 하지 않아 발생한 이슈였죠.
/usr/lib/systemd/network/99-default.link에는 Ubuntu가 네트워크 인터페이스의 MAC 주소를 이해하기 편한 형태로 임의로 변경하도록 하는 방법이 존재합니다. 바로 MACAddressPolicy의 옵션을 none에서 persistent로 변경하는 것이죠.
그러나 쿠버네티스 환경에서는 위 정책이 무조건 none으로 사용되어야 합니다. Pod의 통신을 위해 MAC 주소를 정확하게 알아야 하기 때문이죠. 그런데 이 옵션이 자동 업데이트로 인해 커널 기본 설정들이 오버라이드(Override)되어 초기 기본값인 persistent로 변경되어 버린 것입니다.
하이퍼리즘에 필요한 관리 방식은 수평적으로 확장 가능한 형태이면서 불변성을 가지는 여러 AMI에 대응되는 구조라는 걸 깨닫게 되는 계기였습니다.
최종 운영 전략
- 모듈화:
modules/eks-node를 만들어 OS, AMI, UserData를 규격화했습니다. - 분리: 클러스터의 버전 업데이트 주기와 노드의 AMI 패치 주기는 다릅니다. 이를 별도의 Terraform State로 관리하여, 노드 하나를 추가하거나 수정할 때 클러스터 전체에 영향이 가지 않도록 격리했습니다.
- 예측 가능성: 이제 노드의 추가는 오직
terraform apply를 통해서만 일어납니다. 시스템이 멋대로 판단하여 노드를 끄는 일은 더 이상 없습니다. - Immutable Infrastructure:
unattended-upgrades와 같은 자동 업데이트는 모두 제거하였습니다.
결국 하이퍼리즘의 테라폼은 아래와 같은 구조를 띠게 되었습니다.
├── 노드 프로비저닝
│ ├── Terraform 모듈 구조
│ │ ├── modules/eks-node (공통 노드 모듈)
│ │ ├── kubernetes/nodes/Cluster1-* (Cluster1 노드 정의)
│ │ └── kubernetes/nodes/Cluster2-* (Cluster2 노드 정의)
│ ├── AMI 관리
│ │ ├── EKS 최적화 AMI
│ │ ├── x86_64 및 arm64 아키텍처 지원
│ │ └── SSM Parameter Store에서 최신 AMI 조회
│ └── 노드 보안 설정
│ ├── API 종료 보호 활성화
│ ├── 클러스터 보안 그룹 자동 적용
│ └── IAM 인스턴스 프로파일 연결
올바른 도구를 선택하는 기준
결론적으로 하이퍼리즘에게 있어서 Karpenter는 알맞지 않은 도구였습니다.
그렇다면 우리는 어떤 기준을 가지고서 도구를 선택해야 할까요?
우리의 인프라를 잘 알고 있는지 점검하기
인프라라는 것은 기업별로, 개인별로 다양한 형태가 존재합니다.
전형적인 MSA 형태부터 시작하여, MSA의 기조를 이은 MA 형태의 인프라도 존재합니다.
이런 다양한 챌린지들이 쏟아지는 현업에서 자신의 인프라를 되돌아보는 시간은 무척이나 적어지는 것이 당연한 수순입니다.
도구를 도입하기에 앞서 회고를 통해 현재 나의 인프라를 돌아보는 시간을 가져야 합니다.
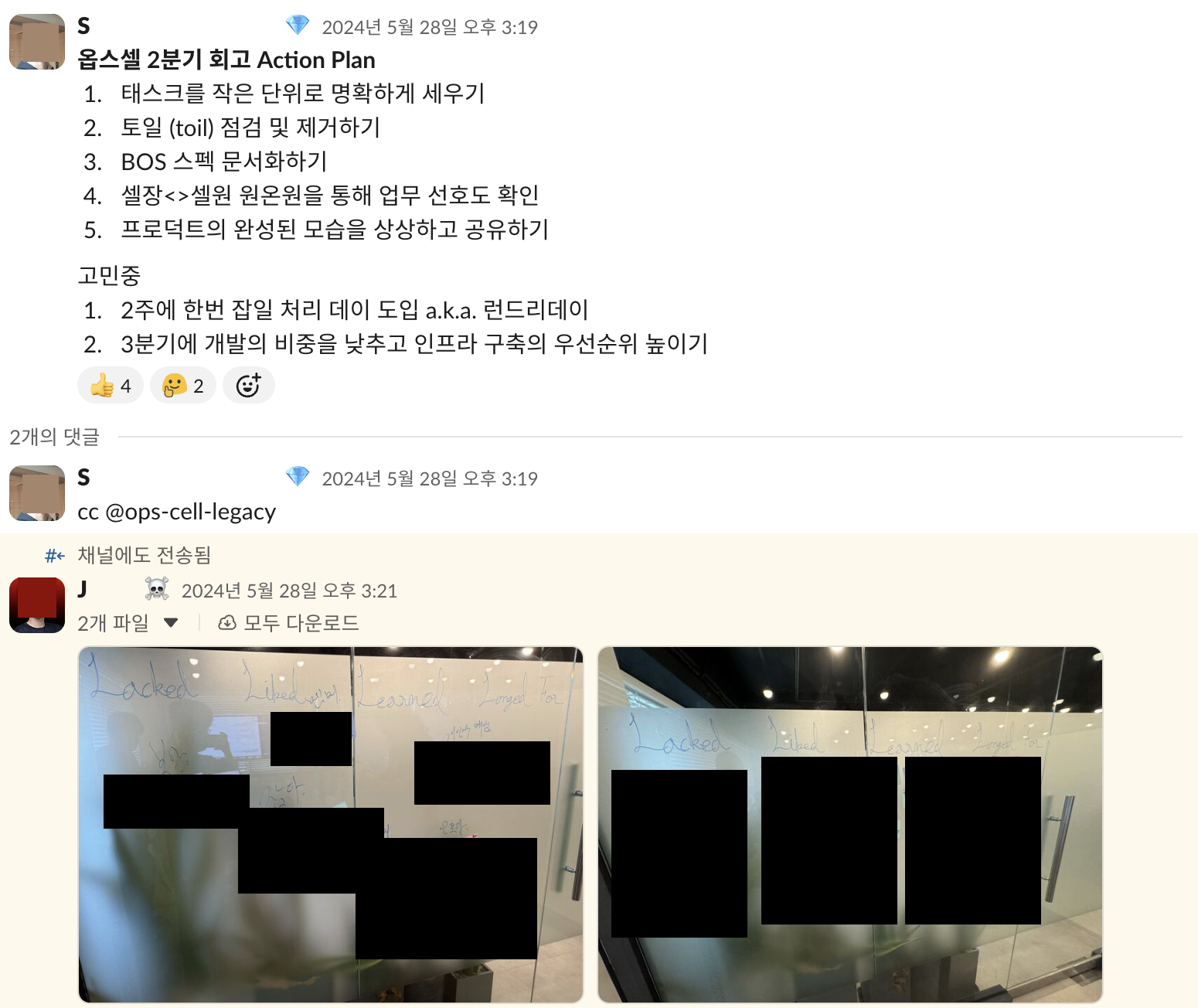
신뢰도 검토하기
새로운 기술이 만들어져서 관심받는 것은 AI 시대에 당연한 흐름이 되었습니다. 늦어지면 뒤처진다는 생각에 섣부르게 신뢰도가 낮은 프로젝트를 인프라로 도입하게 될 경우 다음과 같은 문제가 발생할 수 있습니다.
- Bug Fix의 지연
- CSP와의 호환성 문제
- 메인테이너의 무책임한 방임으로 발생하는 프로젝트 방치
- 늦은 보안 패치
그렇다고 Github Star 수가 높고 사용자가 많다고 위 상황이 발생하지 않는다는 보장은 없습니다. 하지만, 동시에 생태계에서 활동하는 많은 사람이 위 상황이 발생하지 않도록 눈에 불을 켜고 돌아다니기에 이를 잘 활용하는 것도 중요합니다.
One way door인가?
인프라에서의 솔루션 도입과 철수는 달리는 기차의 바퀴를 갈아 끼우는 행위와 같습니다.
한 번 도입하는데 많은 공수가 발생하고 또 제거하는 데는 더 많은 공수가 들어갑니다.
바퀴를 갈아 끼우는 데 있어서 다운타임이 발생하면 이는 B2C는 고객 이탈, B2B는 기업 간 신뢰도 저하 등의 문제가 발생할 수 있습니다. 어느정도 감안하는 것이 올바른 정신이겠으나 그러지 못한 고객과 기업도 존재합니다.
비가역적인 의사결정을 신중히 하는 것이 무엇보다 중요합니다.
마치며
단순한 기술 트렌드를 좇는 것이 아닌, 하이퍼리즘만의 특수한 상황에 가장 적합한 도구를 고민하고 선택했던 과정을 공유해 보았습니다. 인프라 셀은 화려한 자동화 도구보다 더 중요한 가치는 결국 우리 시스템의 본질을 정확히 이해하고, 그에 맞는 '신뢰성'을 구축하는 일이라고 생각하고 있습니다.
하이퍼리즘 인프라 셀은 전 세계 시장을 누비는 트레이더들이 오직 거래에만 집중할 수 있도록, 오늘도 가장 단단하고 예측 가능한 무대를 만들고 있습니다. SRE부터 DevSecOps까지, 저희와 함께 기술적 난제들을 고민하며 인프라의 한계를 넓혀갈 동료를 기다립니다!
하이퍼리즘의 가파른 성장 궤도에 함께 올라타고 싶으신 분들은 언제든 아래 연락처로 편하게 커피챗을 신청해 주세요!
☕ 커피챗 문의 - cto@hyperithm.com
끝까지 긴 글 읽어주신 모든 분께 모두 감사드립니다.
